 Neue Möglichkeiten durch DataBlades:
Neue Möglichkeiten durch DataBlades:
Datenbankdienste als Framework
Die Theorien der relationalen Datenbanken unterscheiden sich deutlich von den Ansätzen der objektorientierten Datenbanken. Während sich die Gelehrten streiten, gewinnt das objektrelationale Paradigma mit evolutionärem Vorgehen und der Vereinigung der Vorteile beider Seiten an Boden.
 Bild 1: Die unterschiedlichen Wege der Datenbanken
Bild 1: Die unterschiedlichen Wege der DatenbankenDie Entwicklung der Datenspeicherung in der Informationstechnologie zeichnet sich durch zunehmende Intelligenz aus, die den für Datenspeicherung und -rückgewinnung zuständigen Software-Subsystemen verliehen wurde. Dies fing mit einfachen Medien wie der Lochkarte an und geht bis zu den heutigen komplexen Datenbanksystemen.

Evolution der Datenspeichersysteme
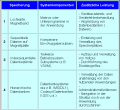 Tabelle 1: Evolution der Datenspeichersysteme
Tabelle 1: Evolution der DatenspeichersystemeTabelle 1 zeigt eine Chronologie des entsprechenden Evolutionsweges. Beginnend mit einfachster Handhabung der Ein- und Ausgabe wurden den Komponenten der Datenverwaltung immer mehr zusätzliche Leistungen übertragen. Sie haben sich dadurch von Routinen, die jeder Programmierer in jeder Anwendung neu schreiben mußte über Makroaufrufe bis zu Subsystemen der Betriebssysteme entwickelt, da sie eine Komplexität erreichten, die zur Optimierung einen Entwurf durch die Betriebssystemspezialisten und eine einmalige Implementierung im Betriebssystem anboten. Im weiteren Verlauf wurde die Datenverwaltung in der Implementierung von der konkreten Anwendung abgekoppelt und erhielt außer einer standardisierten Datenzugriffs- und Datenmanipulationsoberfläche eine Vielzahl weiterer Aufgaben zur Verwaltung und Administration der Daten übertragen. Die Datenbanken waren geboren. Hiermit hatte diese Systemkomponente eine Komplexität erreicht, die sogar den Betriebssystemen entwachsen war. Hersteller und unabhängige Anbieter brachten umfangreiche Systeme auf den Markt, die dem Anwendungsentwickler eine Fülle neuartiger Möglichkeiten boten und die den Anwendungen selbst einen wesentlichen Schub in Richtung der integrierten Verarbeitung verliehen.
Der vorliegende Beitrag befaßt sich mit den Stufen 5 bis 7 aus Tabelle 1, also der aktuellen Entwicklung, die relationale Datenbanksysteme als "state of the art" akzeptiert und sich nun zu neuen Ufern aufmacht. Hierbei ist das verheißungsvolle Ufer noch nicht auszumachen, die beteiligten Parteien sind noch dabei, ihren Standort und ihre Werbestrategien zu definieren.
Der Unterschied liegt in der Speichermethode
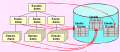 Bild 2: Relationale Datenspeicherung
Bild 2: Relationale DatenspeicherungRelationale versus objektorientierte Speicherung ist die Frage, welche die Gemüter der heutigen Datenbank-Päpste bewegt. Was ist hierbei der Unterschied? An dieser Stelle muß unterstrichen werden, daß es sich nicht um die Infragestellung des objektorientierten Paradigmas handelt, sondern lediglich um die Methode, wie die Daten aus Objekten am besten zu speichern sind.
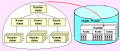 Bild 3: Objektorientierte Datenspeicherung
Bild 3: Objektorientierte DatenspeicherungBild 2 und Bild 3 stellen die verschiedenen Vorgehensweisen gegenüber. Als Beispiel ist eine einfache Datenstruktur einer Bank gegeben, die Kundendaten enthält, dem Kunden zugeordnete Kontodaten und für jedes Konto wiederum die Daten von einzelnen Kontoumsätzen. Das gesamte ergibt eine Hierarchie, die über Beziehungen verknüpft ist.
In der relationalen Datenspeicherung (Bild 2) wird nun jede Datenart, Klasse genannt, in eine spezielle Datenbanktabelle gespeichert. Die Darstellung der Beziehungen erfolgt nicht explizit, sondern über den Dateninhalt von "Fremdschlüsseln", die die einzelne Datenzeile in der verknüpften Tabelle eindeutig identifizieren. Dies sind in unserem Beispiel für die Kontodaten die Kunden-Nummer aus den Kundendaten und für die Umsatzdaten die Konto-Nummer aus den Kontodaten.
 Kasten 1: Zerlegen Sie Ihr Auto beim Parken ?
Kasten 1: Zerlegen Sie Ihr Auto beim Parken ?Die relationale Datenspeicherung erlaubt auf diese Weise eine sehr hohe Flexibilität bei Erweiterungen und Änderungen der Datenstruktur. Verknüpfungen sind nicht explizit gesetzt, sondern ergeben sich dynamisch aus dem Dateninhalt. Dadurch lassen sie sich leicht neu ordnen und können über eine mengenorientierte Abfrage wie SQL leicht nach vielen verschiedenen Gesichtspunkten neu zusammengestellt und abgefragt werden. Der Nachteil ist die zersplitterte Speicherung von Daten, die zu einem Objekt, hier dem Kunden, gehören. Bei der Abfrage aller Daten des Kunden bedeutet dies ein neues Zusammenfügen der Hierarchie aus einzelnen Tabellen. Auch wenn die Bereitstellung durch eine Mengenabfrage geschieht, müssen die Informationen über Schleifenkonstrukte nacheinander abgeholt werden. Die mengenorientierte Speicherung eines komplexen Objektes in eine relationale Datenbank ist zudem nicht möglich. Jedes Datenelement muß gezielt in die jeweilige Tabelle geschrieben werden. Anhänger der objektorientierten Speicherung machen sich oft über die relationale Vorgehensweise lustig (siehe Kasten "Zerlegen Sie Ihr Auto beim Parken?"). Der Vergleich hinkt aber gewaltig und könnte, wie später gezeigt, in sein Gegenteil umschlagen.
Die objektorientierte Datenspeicherung (Bild 3) geht davon aus, daß zusammenbleibt, was zusammengehört und speichert das gesamte komplexe Objekt als Struktur an einer Stelle. Die Verknüpfung geschieht durch interne Pointer, die sich speziell auf das gespeicherte Objekt und dessen aktuelle Struktur beziehen. Vorteile sind die schnelle Speicherung und Bereitstellung. Die Speicherung ist als Fortsetzung der objektorientierten Betrachtung ausgelegt und macht ein Objekt "persistent". Die Bereitstellung eines Objektes kann nach dieser Speicherung gewissermaßen "mundgerecht" für die objektorientierte Sprache aufbereitet und mit Pointern versehen erfolgen. Das ist effizient und erleichtert die Programmerstellung. Die sich daraus ergebende letzte Konsequenz, auch die Methoden bei jeder Objektinstanz zu speichern, beziehungsweise aus Kapazitätsgründen eine Versionierung bei geänderten Methoden durchzuführen, wird allerdings nicht gezogen.
Der Pferdefuß ist, daß das einmal in seiner vollen Pracht und Schönheit gepeicherte Datenobjekt immer in dieser Zusammensetzung gelesen werden muß, da es eine Einheit bildet. Eine gezielte Auswertung der einzelnen Hierarchieebenen wie bei der relationalen Speicherung oder die Nutzung geschachtelter Objektebenen im Rahmen der Komponententechnik (siehe auch Beitrag " Komponenten und Skalierbarkeit: Softwareteile in allen Größen") sind hierbei nicht möglich.
Als Ergebnis des Vergleichs ist festzuhalten, daß die Unterschiede erheblich sind und die Entscheidung auch für den objektorientierten Ansatz nicht einfach. Beide Ansätze haben Vor- und Nachteile und bergen Zielkonflikte, die sich auf Anhieb nicht lösen lassen.
OO-Datenbanken sind nicht die Krönung des Paradigmas
Die bisher angeführten Argumente lassen vermuten, daß es im objektorientierten Ansatz nicht damit getan ist, Objekte einfach persistent zu machen und das ganze dann eine objektorientierte Datenbank zu nennen. Die Zusammenhänge sind komplexer. Objekte sind idealerweise aus Teilobjekten aufgebaut und diese Teilobjekte sind wiederverwendbar. Hierbei brauchen die Teilobjekte nicht unbedingt äußerliche Ähnlichkeiten mit dem Gesamtobjekt zu haben. Hier wie auch in der Systemtheorie ist das Ganze mehr als die Summe seiner Teile. Mit diesem Ansatz der Wiederverwendung hat die objektorientierte Datenspeicherung gemäß Bild 3 ihre Probleme.
Sehen wir uns einmal die relationale Speicherung an. Wir können die Datenhierarchie als Objekthierarchie sehen. Umsätze und Konten sind jeweils Objekte einer niedrigeren Hierarchieebene, die mit dem Kunden zum Objekt "Kunde" verschmelzen, aber dennoch getrennt wiederverwendet werden können. Die einzelnen Umsatz- und Kontendaten werden dann zu Instanzen ihrer Klassen. Nun sind wir über einen konsequente Ausbau der objektorientierten Struktur mit ihrem Anspruch auf Wiederverwendung der Objekte und schichtenweisen Objekt-Aggregation plötzlich bei der relationalen Datenspeicherung gelandet.
Heißt das, daß die relationale Datenbank die bessere objektorientierte Speicherung ist? Müssen wir erst unsere Objekte normalisieren und dann das Prinzip des "data hiding" anwenden? Die Wahrheit liegt wahrscheinlich wie so oft in der Mitte. Der nachfolgend vorgestellte Weg ist eine Chance, die Vorteile beider Systeme zu vereinen, ohne die Nachteile allzusehr zu übernehmen. Aus der Schlacht der Systeme dürfte eine evolutionäre Entwicklung werden. Und das ist gut so, Richtungskämpfe und Glaubenskriege gab und gibt es in der Informationstechnologie genug. Die Datenbanktechnologie ist eine so wichtige Komponente und hat so viele Rückwirkungen auf die Anwendungen, daß wir uns keine langwierigen Auseinandersetzungen leisten können.
Der Königsweg könnte objektrelational sein
Zugegebenermaßen kann die Normalisierung der Relationen, nach der reinen Lehre implementiert, sehr zersplittert und dadurch aufwendig werden. Viele Systemdesigner weichen deshalb bereits heute in ihrer physikalischen Implementierung vom logischen Modell ab. Da der rein objektorientierte Ansatz, wie wir bisher sahen, entweder zu mächtige Einheiten bildet und für Wiederverwendung nicht brauchbar ist oder durch die Hintertür bei der relationalen Speicherung landet, wird ein Mittelweg gesucht. Der Mittelweg heißt, die Objekte so klein zu schneiden, daß ihre Bestandteile nicht mehr wiederverwendet werden müssen. Sind diese Objekte komplex, werden sie objektorientiert gespeichert, im anderen Falle relational. Die Einheiten in objektorientierter Speicherung können durch die Anreicherung mit Schlüsselwerten (als Repräsentation für das Gesamtobjekt) in die Relationen eingegliedert werden. Auf diese Weise werden sie auch wieder der mengenorientierten Abfrage über SQL zugänglich.
Dieser Weg wird derzeit von den objektrelationalen Datenbanken begangen. Sie tun das eine, ohne das andere zu lassen und fahren anscheinend gut damit. Der objektrelationale Ansatz kann mit Fug und Recht von sich behaupten in das objektorientierte Paradigma zu passen, eventuell sogar universeller als die bisherige Reinkultur.
Blobs und deren Zähmung
 Bild 4: Beispiel einer objektrelationalen Speicherung
Bild 4: Beispiel einer objektrelationalen SpeicherungWie sieht nun die Realisierung des objektrelationalen Ansatzes in der Praxis aus. Die relationalen Datenbanken haben sich in der Vergangenheit bereits ein Stück in diese Richtung bewegt, ohne es konkret zu propagieren. Mit dem Fortschritt der Bildverarbeitung wurde der Wunsch laut, auch Bilder in einer Datenbank abzuspeichern. Da diese aber keine Standard-Datenformate sind und der Umfang eines solchen Elementes auch die Größenbeschränkungen herkömmlicher Datenbankfelder bei weitem sprengen kann, wurden die "BLOBs" eingeführt.
Ein BLOB ist nun kein Sahnezusatz zu einem grünen Gemüse, sondern ein "Binary Large OBject". Von der Datenbank wird also ein unstrukturiertes Feld mit sehr hohem Fassungsvermögen (teilweise bis 2 GB) wie ein Container unter einem Feldnamen gespeichert und wieder bereitgestellt. Die innere Struktur muß der Anwendung bekannt sein. Auf diese Weise können auch komplexe Objekte in einer relationalen Datenbank gespeichert werden. Da das BLOB zu einer Zeile der Relation gehört, können ihm auch Fremdschlüssel zugeordnet und es damit in weitere Relationen eingeordnet werden.
Bild 4 zeigt in Anlehnung an die früheren Beispiele eine mögliche Art der Speicherung von Objekten in einer relationalen Tabelle. Zu den herkömmlichen Daten wie Kunden-Nummer und Anschrift wird ein graphisches Objekt, das Bild des Kunden sowie ein komplexes Objekt, die Umsatzstatistik des Kunden in Form von verdichteten Zeitreihen in BLOBs gespeichert. Spezielle Teile der Anwendung bearbeiten und interpretieren die BLOBs.
Der nächste Schritt liegt jetzt nahe. Die Datenbanken hatten seit jeher die Aufgabe, den Anwendungsentwickler vom Datenhandling zu entlasten. Ein weiterer Schritt auf diesem Wege war, die Behandlung der verschiedenen Objektklassen in den BLOBs bausteinartig in die Datenbank zu integrieren und die Anwendung über standardisierte Schnittstellen leichter auf die komplexe Struktur zugreifen zu lassen. Die objektrelationale Datenbank war erfunden.
So vernünftig der objektrelationale Ansatz aussieht, der auf Evolution statt auf Revolution setzt, die Umsetzung ist noch am Anfang. Der Kasten "Nachteile heutiger objektrelationaler Datenbanken" beinhaltet hauptsächlich strategische Gesichtspunkte. Der Anwender muß sich im Klaren sein, daß er sich derzeit noch in eine Abhängigkeit begibt und für seinen Pionierstatus zu investieren hat. Andererseits kann er frühzeitig die aller Wahrscheinlichkeit nach künftige Richtung der Datenbankentwicklung verfolgen und entsprechende Kenntnisse aufbauen. Mit Verstand verfolgt sollte dies ein guter Weg sein.
Nachteile heutiger objektrelationaler Datenbanken
|
DataBlades erledigen die Arbeit
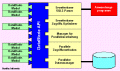 Bild 5: Schema der DataBlade-Technologie
Bild 5: Schema der DataBlade-TechnologieBeispielhaft soll die Implementierung einer objektrelationalen Datenbank am Muster des neuen Informix Universal-Servers dargestellt werden. Dieses neue Produkt der Firma Informix entstand aus einer Verschmelzung der bisherigen relationalen Datenbank mit einem objektrelationalen Datenbanksystem. Das aus einem Forschungsprojekt als "Postgres" hervorgegangene und von der Firma "Illustra" weiterentwickelte System wurde (nach Aufkauf der Firma Illustra durch Informix) in die Informix-Datenbank eingebracht.
Als Ergebnis übernehmen sogenannte "DataBlades", die über ein API (Application Program Interface) in die Datenbank eingehängt werden, die Arbeit der Interpretation und Verwaltung der Objekte. Pro Objektklasse wird das entsprechende DataBlade eingehängt. Das Anwendungsprogramm greift über eine Erweiterung der SQL-Sprache (SQL3) auf die Datenbank zu. Auf diesem Wege ist der Zugriff von der Gestaltung des DataBlades entkoppelt. Standards für die DataBlade-API verhindern zumindest innerhalb dieses Datenbanksystems bei den unterschiedlichen, von Informix, Fremdfirmen und auch den Anwendern entwickelten DataBlades ein auseinanderlaufen der Schnittstellen.
Die Firma Informix hat die Nachteile einer solch "einseitigen" Standardisierung erkannt und bietet deshalb ihre API-Schnittstelle als "offene Schnittstelle" an, für die andere Datenbankhersteller eine Lizenz erwerben können. Auf Basis dieser Vorgehensweise wird angestrebt, im Verbund einen de-facto-Standard zu schaffen.
Bild 5 stellt den Aufbau des objektrelationalen Universal-Servers mit DataBlade-Technologie dar. Auf der einen Seite der API werden die DataBlades in standardisierte Schnittstellen eingehängt. Auf der anderen Seite übernehmen die Datenbankdienste die Grundleistungen des Systems. DataBlades sind bereits für eine Vielzahl von Anwendungsgebieten verfügbar oder in Entwicklung. Eine Auswahl wird in dem entsprechenden Kasten aufgeführt. Eine zusätzliche Möglichkeit, Funktionalität in der Datenbank anzureichern, sind die Erweiterungsmöglichkeiten der Basisdienste (siehe entsprechender Kasten). Hier kann der Anwender wirklich grundlegende Funktionalitäten zusätzlich implementieren und für alle übrigen Komponenten verfügbar machen. Derzeit wird beispielsweise eine Indexmethode entwickelt, die außer den derzeitigen linearen Indizes noch zwei- oder dreidimensionale Indizes verwalten kann (z.B. für räumliche oder flächenbezogene Daten im Vermessungswesen).
Auswahl verfügbarer DataBlade-Anwendungen
|
Erweiterbarkeit der Datenbank-Basisdienste
|
Datenbanksysteme als Framework
Die Datenbankentwicklung macht mit den neuesten Produkten eine interessante Metamorphose durch. Die Datenbanken entwickeln sich von monolithischen Gebilden zu Rahmendiensten, sogenannten "Frameworks". Die Hersteller öffnen sich und lassen die bausteinartige Erweiterung ihrer Datenbanken zu. Das bisherige Datenbanksystem stellt Standarddienste wie die bekannten relationalen Funktionen sowie Datenverwaltung, Logging, Recovery und Administration bereit und der Anwender kauft die für ihn erforderlichen Erweiterung in Form von DataBlades oder Erweiterungen der Basisdienste dazu oder implementiert sie selbst. Auf diese Weise wird sich ein dynamischer Markt entwickeln, der bausteinartigen Aufbau und Wiederverwendung im Sinne der Objektorientierung fördert.
All dies ist derzeit noch zu einem gewissen Teil Zukunftsmusik. Der Ansatz ist vorhanden, die bereits geschilderten strategischen Nachteile werden sich beim Einstieg weiterer Hersteller vermindern. Es kommt im wesentlichen darauf an, ob sich die bisher vorgeschlagenen Standards durchsetzen, oder ob es einen langen Stellungskrieg der Hersteller um die Durchsetzung ihrer Interessen gibt, bei dem alle nur verlieren können. Die Qualität eines Datenbank-Frameworks wird sich in Zukunft daran messen, wie viele Grundfunktionen geboten werden, welche Zusatzfunktionen auf dem Markt verfügbar sind und wie stabil und zukunftssicher sich das Gesamtgebilde erweist. Bei zu geringem Angebot kommt der Anwender doch wieder in die Situation, sich seine Datenbank, wenn auch in Teilen, selbst schreiben zu müssen.
Die OO-Grundsätze werden gewahrt
Von den Ansätzen der objektrelationalen Datenbanken kann mit gutem Gewissen gesagt werden, daß die Grundsätze der Objektorientierung gewahrt werden. Die Wiederverwendung wird nicht beeinträchtigt und die Speicherung komplexer Objekte ist möglich. Eine leistungsfähige und konsequent realisierte Datenbank für echte Objekte mitsamt der Methoden über mehrere Versionen steht ohnehin noch in den Sternen.
Die Nutzung der objektrelationalen Datenbank wird zum Prüfstein für leistungsfähiges OO-Design werden. Aufgrund der aufgezeigten Zielkonflikte wird das Design nicht einfacher.
Was bringt die Zukunft ?
Der Blick in die IT-Kristallkugel hat sich schon so oft als Reklametrick herausgestellt. Es soll aber doch eine Prognose gewagt werden, wie sich die Wege der Datenbanken weiterentwickeln dürften. Der objektrelationale Ansatz als Verschmelzung der Wege relational und objektpersistent (weiter oben wurde ja festgestellt, daß die aktuell herrschende Meinung von objektorientierter Speicherung wohl doch nicht so ganz mit den Grundsätzen der Objektorientierung vereinbar ist) auf einem evolutionären Weg sollte die besseren Chancen haben.
Für den strategisch planenden Anwendungsdesigner ist es zum heutigen Zeitpunkt wichtig, sich trotzdem seine Unabhängigkeit zu bewahren. Im Rahmen einer sachgerechten Datenkapselung muß die Datenbasis austauschbar sein. Nur so kann die Anwendung stabil bleiben. Es schadet beim aktuellen Entwicklungsstand nichts, einige Zwischenstecker mehr zu konzipieren und zu implementieren.
Die Datenbank-Welt selbst wird in Zukunft zwar wesentlich leistungsfähiger, aber auch wesentlich komplexer werden. Der Designer kann sich nicht auf die Funktionalität "seiner" Datenbank zurückziehen, sondern muß wesentlich mehr wissen, um die besten Zusätze auf dem Markt zu finden und einzusetzen. Er wird vom Hausherrn, der das Haus schlüsselfertig übernimmt, wieder zum Architekten. Das Gebiet wird zum einträglichen Feld sowohl für sachkundige Berater als auch für Trittbrettfahrer. Den Willen zur konsequenten Vorgehensweise, die exakte Formulierung der Anforderungen und letzendlich die Entscheidung kann aber auch ein noch so guter Berater nicht abnehmen.